Подсчет строк, слов и символов в файле
Написать программу, которая считает количество
строк, слов и символов
в текстовом файле.
Решение задачи на языке программирования Python
Цикл for языка Python извлекает из файлового объекта данные построчно (одну строку на каждой итерации цикла). Таким образом, количество итераций цикла определит количество строк в файле.
Встроенная функция len() языка Python считает количество элементов в передаваемом в нее объекте. С ее помощью находится количество символов в каждой строке.
Строковый метод split() разбивает строку на части. По-умолчанию разделение происходит по местам расположения пробелов в строке. Таким образом, мы можем определить количество слов в каждой строке, посчитав с помощью len() слова в получившемся после применения split() списке.
На каждой итерации цикла мы должны добавлять полученные значения к переменным, хранящим общие количества строк, слов и символов.
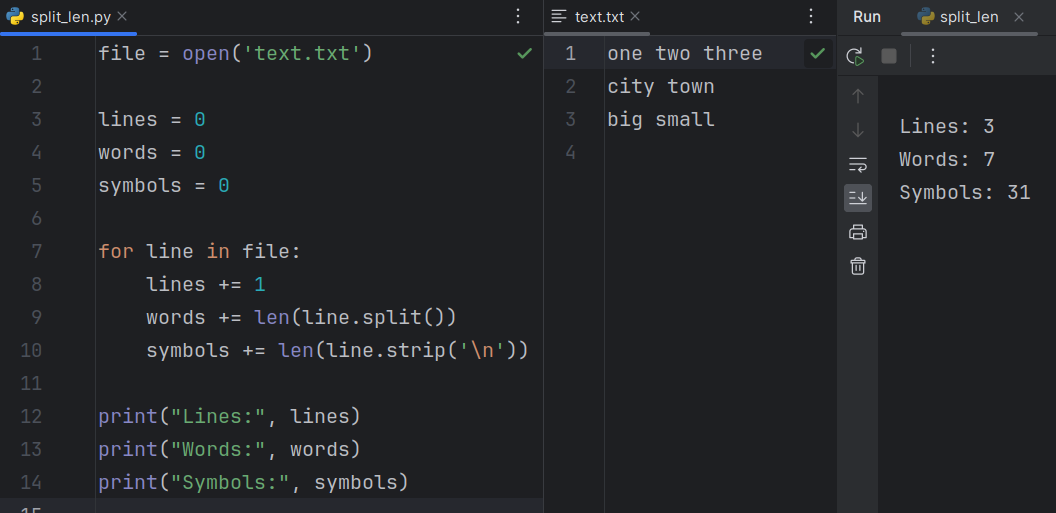
file = open("text.txt") lines = 0 words = 0 symbols = 0 for line in file: lines += 1 words += len(line.split()) symbols += len(line) print("Lines:", lines) print("Words:", words) print("Symbols:", symbols)
Пусть содержимое файла text.txt будет таким:
one two three city town big small
Тогда программа даст следующий результат:
Lines: 3 Words: 7 Symbols: 34
Символами считаются не только буквы, также пробелы и переходы на новую строку (символ '\n'). Если требуется не учитывать переход на новую строку как символ, его можно "отрезать" с помощью строкового метода strip(). Делается это перед тем, как строка передается в функцию len(): symbols += len(line.strip('\n')).
Если данную задачу надо решить без использования продвинутых возможностей (встроенных функций и методов) языка программирования Python, а в рамках изучения алгоритмов или на более "низком" уровне (обычно в таких случаях текст перебирается посимвольно), то программа может выглядеть так:
file = open('text.txt') text = file.read() lines = 0 words = 0 symbols = 0 in_word = False for char in text: symbols += 1 if char == '\n': lines += 1 if char != ' ' and char != '\n' and in_word == False: words += 1 in_word = True elif char == ' ' or char == '\n': in_word = False print("Lines:", lines) print("Words:", words) print("Symbols:", symbols)
Здесь на каждой итерации цикла мы имеем дело не с целой строкой, а с очередным символом. При этом увеличиваем на единицу переменную, хранящую количество символов, и, если текущий символ — это переход на новую строку, переменную для подсчета количества строк.
Для подсчета слов требуется определить в программе еще одну переменную, в которой будет храниться "сигнал", находимся ли мы внутри слова. Если это так, то очередной непробельный символ не следует считать началом нового слова и не надо увеличивать счетчик слов.
Алгоритм подсчета слов в программе выше следующий. Если текущий символ не пробел и не переход на новую строку, и ранее мы находились вне слова (in_word == False), то есть соблюдены все три условия сразу, значит началось новое слово. Поэтому увеличиваем счетчик слов и устанавливаем in_word в значение True. Последнее действие позволит на следующей итерации цикла, при условии обработки второй и последующих букв слова, не соблюдаться условию in_word == False и не увеличивать счетчик слов.
Мы "сбрасываем" in_word в False, только когда встречаем пробельный символ или переход на новую строку (любое одно из двух условий).
Программа выше, также как в первом варианте, считает переход на новую строку за символ. Если требуется его исключить, можно поместить увеличение значения счетчика символов в ветку else:
... for char in text: if char == '\n': lines += 1 else: symbols += 1 ...
Если очередной символ — это переход на новую строку, увеличивается счетчик строк. В остальных случаях, — счетчик символов.
Если файл большой, то считывать сразу все его содержимое в строковую переменную (text = file.read()) неблагоразумно. Если читать файл посимвольно (file.read(1)), то условием завершения работы цикла будет момент возврата методом read() пустой строки, что означает конец файла (в других языках может быть специальный символ конца файла, доступный через идентификатор EOF — end of file).
lines = 0 words = 0 symbols = 0 in_word = False with open('text.txt') as file: while True: char = file.read(1) if char == '': break symbols += 1 if char == '\n': lines += 1 if char not in (' ', '\n') and not in_word: words += 1 in_word = True elif char in (' ', '\n'): in_word = False print("Lines:", lines) print("Words:", words) print("Symbols:", symbols)
В этом примере для открытия файла используется оператор with, который рекомендован для работы с файлами. Выражения char not in (' ', '\n') and not in_word и char in (' ', '\n') по смыслу аналогичны соответствующим логическим выражениям из предыдущих вариантов программы.