Утилита grep ‒ поиск по содержимому файлов
Если с помощью программы find файлы ищут, то утилита grep (имя происходит от команды g/regular-expression/p редактора ed) выполняет поиск по их содержимому. Например, надо найти файл, содержащий тот или иной текст. Или в одном файле найти строки, включающие конкретное слово. Также grep используется для фильтрации вывода других команд. При этом вывод этих команд перенаправляется на ввод к grep. Сам же grep тоже может перенаправлять свой вывод, например, в файл.
Пусть у нас есть каталог с HTML-файлами, и мы хотим узнать используемую версию языка HTML. Для этого не обязательно просматривать все файлы. Достаточно посмотреть любой один и найти в нем строку, начинающуюся с "<html".
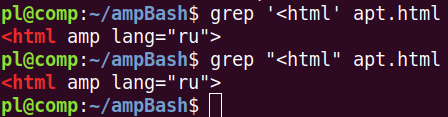
Команде grep первым аргументом передается то, что мы ищем. Вторым – где мы ищем (при этом можно передать не один, а несколько файлов). Первый аргумент в данном случае надо заключить в кавычки из-за символа "<", второй – необязательно. В выводе искомая подстрока подсвечивается красным, но строка выводится целиком.
Если мы хотим посмотреть окружение этой строки на пару строчек вверх и вниз, то используем ключ с числом, которое указывает количество захватываемых окружающих строк.
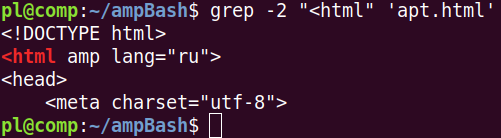
Если перед числом поставить A или B, то дополнительные строки появятся только снизу или только сверху соответственно.
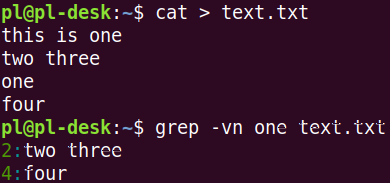
Снова ищем вхождения подстроки в файл. Ожидая несколько совпадений, с помощью ключа -n узнаем номера строк. Они выводятся перед строками:

Если надо выяснить только количество вхождений, используется ключ -c:

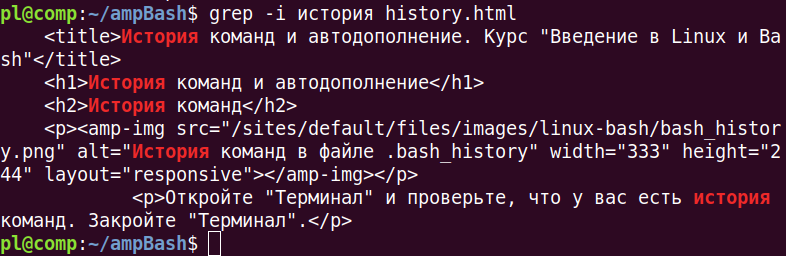
Для игнорирования регистра букв, необходим ключ -i:
Ключ -v позволяет искать от обратного, то есть строки, не соответствующие шаблону.
Основная мощь утилиты grep заключается в возможности использования шаблонов и регулярных выражений (описателей строк), что позволяет искать сразу в нескольких файлах, а также искать не точное соответствие, а примерное.
Шаблон используется для имен файлов. Его обрабатывает командная оболочка Bash. Искомая подстрока описывается регулярным выражением, которое разбирается самой утилитой. Регулярные выражения – это отдельная большая тема. Они бывают простыми, или базовыми, и расширенными. Grep поддерживает оба варианта. По умолчанию используется базовый, для расширенного следует добавить ключ -E.
Если надо осуществить поиск в нескольких файлах каталога, их имена можно задать с помощью шаблона:
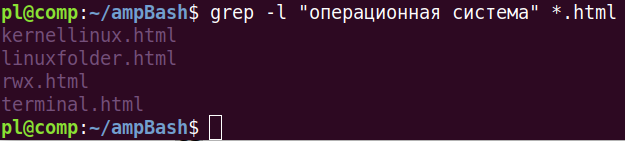
Ключ -l используется, чтобы выводить только имена файлов. На обработку передаются все файлы текущего каталога, соответствующие шаблону *.html. С другой стороны ключ -r позволяет искать рекурсивно в каталогах. Поэтому если предполагается обойти все файлы текущего каталога и вложенных, лучше делать так:
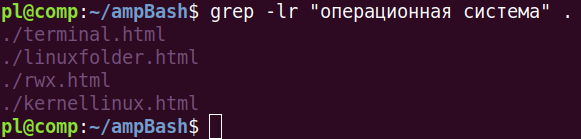
Точка в конце – это адрес текущего каталога. Вместо нее может быть указан адрес любого другого каталога.
Пример использования утилиты grep с простым регулярным выражением:
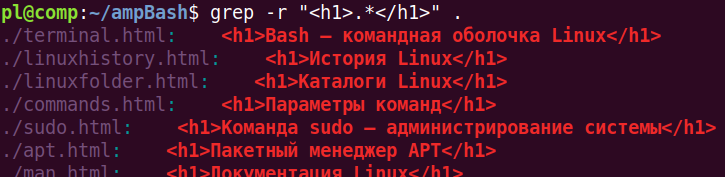
Мы вывели заголовки из всех файлов текущего каталога. Регулярное выражение .* обозначает произвольное количество любых символов. Точка – это любой одиночный символ; звезда – любое количество указанного перед ней символа.
Пример реджекса с перечислением допустимых символов:
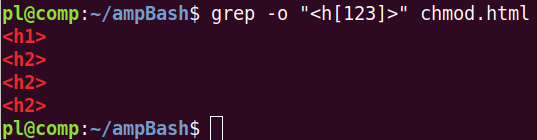
Здесь регулярное выражение – это [123]. Мы узнаем структуру заголовков в файле. Ключ -o позволяет выводить не целые строки, а только совпавшие подстроки.
Символ "^" в регулярных выражениях обозначает начало строки. Допустим, мы хотим посмотреть только список каталогов текущего. В таком случае можно отфильтровать вывод команды ls через утилиту grep:
$ ls -l | grep '^d' drwxrwxr-x 3 pl pl 4096 мар 31 2024 amp-optimizer drwxrwxr-x 9 pl pl 4096 мая 24 2024 ckeditor_tests drwxrwxr-x 4 pl pl 4096 июн 6 00:21 html_templates drwxrwxr-x 3 pl pl 4096 мая 11 2024 material-design_tests