Знакомство с потоковым редактором sed
Поиск по тексту нередко предполагает последующую замену текста или какое-либо другое редактирование. В этом смысле sed – своего рода логическое продолжение grep'а.
Sed – это потоковый текстовый редактор. Потоковый, потому что не загружает весь текст в память, как обычный редактор, а читает его построчно, в потоке. При этом применяет к каждой строке набор команд, описанных программистом заранее. Отсюда следует, что sed имеет свой, хоть и небольшой, язык программирования. Пример:
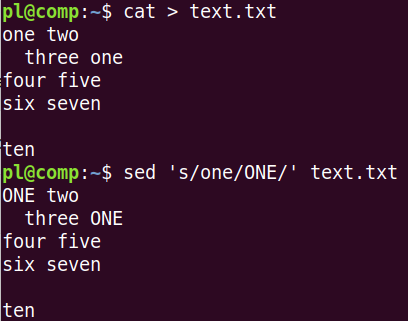
С помощью команды cat был создан файл text.txt. Потом с помощью sed мы заменили слово 'one' на 'ONE'. Результат обработки был выведен на экран. Сам файл остался без изменений.
Если требуется сохранить отредактированный вариант, то вывод следует перенаправить в файл.
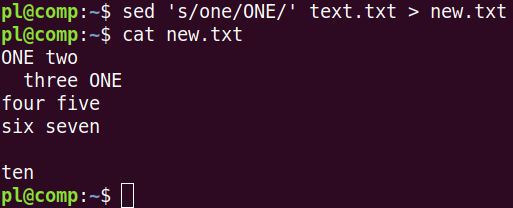
Также можно использовать ключ -i:
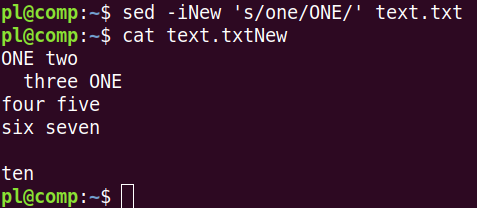
Суффикс после -i будет добавлен к новому файлу. Если же использовать -i без суффикса, то произойдет перезапись существующего файла:
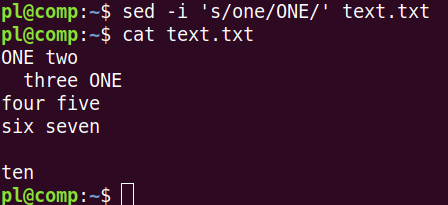
Выражение 's/one/ONE/' – это одна команда. Символ s в начале указывает, что надо найти строку, стоящую после первого слэша, и заменить ее строкой, стоящей после второго. Поскольку sed'у можно передавать несколько команд, то их разделяют точкой с запятой. Также в этом случае потребуется ключ -e.
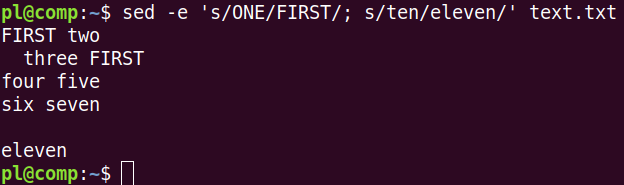
С другой стороны можно заранее подготовить файл с командами, разделяя команды переходом на новую строку. При использовании файла указывается ключ -f.
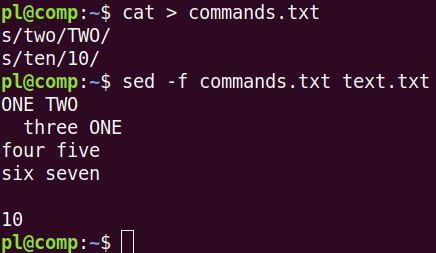
Команда вида 's/one/two/' заменяет в каждой строке только первое вхождение 'one'. Однако в строке таких подстрок может быть несколько. Чтобы заменить все вхождения, после последнего слэша в команде пишется флаг g.
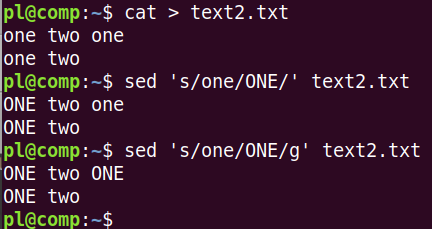
Если надо заменить подстроку, в которой используется символ слэша, его экранируют обратным слэшем. Другой способ – использовать в качестве разделителя частей команды не слэш. Sed считает разделителем любой символ перед искомой строкой.
Все это вершина айсберга. Sed включает множество возможностей – замена только в определенной строке, замена целой строки, работа с диапазонами строк, удаление и вставка строк и другое.
Как и в случае с grep в качестве подстрок часто используют регулярные выражения:
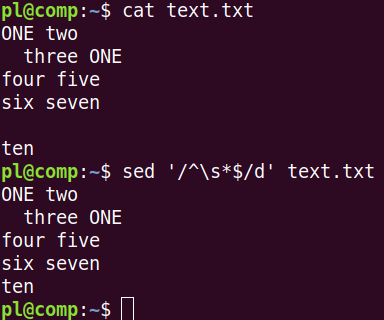
В примере регулярное выражение '^\s*$' ищет пустые строки, а инструкция d удаляет их.