Агрегирование и группировка в SQL и SQLite
Как быть, если надо посчитать общее количество строк таблицы или найти запись, содержащую максимальное значение, или посчитать сумму значений столбца? Для этих целей в языке SQL предусмотрены различные функции агрегирования данных. Наиболее используемые – count, sum, avr, min, max. Используют их совместно с оператором SELECT.
Вывод количества столбцов таблицы:
SELECT count() FROM pages;
Поиск максимального ID:
SELECT max(_id) FROM pages;
Количество различных вариантов значения столбца:
SELECT count(DISTINCT theme) FROM pages;
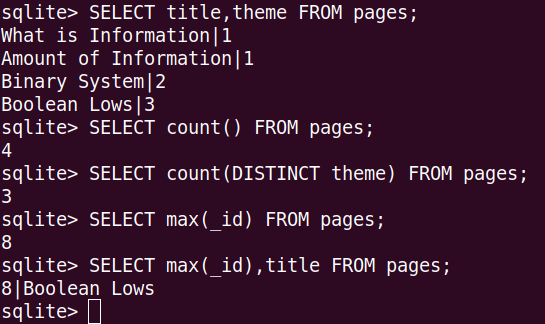
На скрине команда с DISTINCT возвращает 3 потому, что у нас встречается три разных значения в столбце theme – это значения 1, 2 и 3. Тема 1 встречается у двух записей, но благодаря агрегированию они учитываются как одна.
Использование директивы DISTINCT перед именем столбца приводит к выводу его различающихся значений. Например, мы хотим узнать, какие темы используются в таблице pages:
sqlite> SELECT DISTINCT theme FROM pages; 1 2 3
Если в функцию count передается просто имя столбца, например count(theme), то она возвращает количество записей с не NULL значениями. Если в указанном столбце нигде не встречается NULL, то результат будет совпадать с общим количеством записей.
Перед агрегированием можно выполнить фильтрацию. Данная команда посчитает количество страниц определенной темы:
sqlite> SELECT count() FROM pages WHERE theme = 1; 2
Обратим внимание, в SQL сначала выполняется фильтрация, то есть оператор WHERE. И только после этого агрегирование, то есть функция count(). Таким образом, из всей таблицы сначала фильтруются записи с темой 1. После этого считается их количество.
Если было бы наоборот, то приведенная выше команда не сработала, потому что функция count() вернула бы число-количество строк таблицы, и фильтровать из него было бы уже нечего.
В SQL кроме функций агрегирования есть оператор GROUP BY, который выполняет группировку записей по вариациям заданного поля. То есть GROUP BY группирует все записи, в которых встречается одно и то же значение в указанном столбце, в одну строку. Так следующая команда выведет не количество тем, а их номера:
sqlite> SELECT theme FROM pages GROUP BY theme; 1 2 3
Таким образом мы можем узнать, на какие темы имеются страницы в базе данных.
Часто группировка и агрегирование фигурируют в одной команде. Например, надо выяснить количество записей в каждой группе:
sqlite> SELECT theme,count() FROM pages GROUP BY theme;
Здесь будут выведены два столбца. В первом будет номер темы, во втором – количество страниц темы. Функция count() будет выполняться после группировки по темам. Она будет считать количество записей в каждой теме.
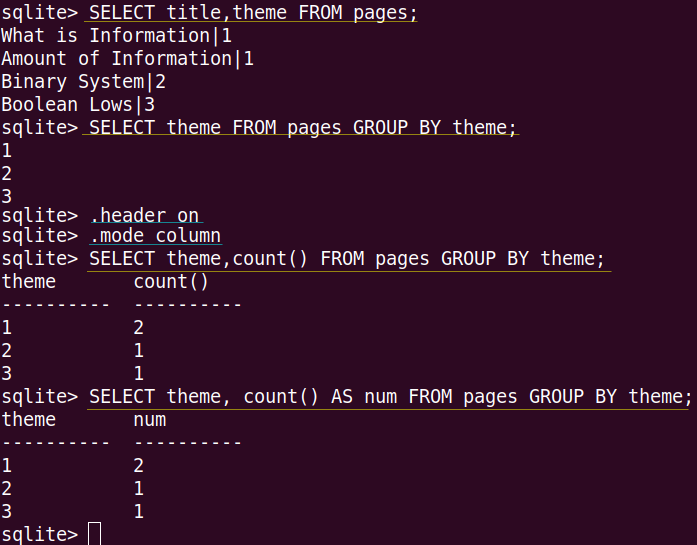
На скрине в последней команде используется переименование столбца count() в столбец num. Делается это с помощью ключевого слова AS.
Пример совместного использования группировки и функции max:
sqlite> SELECT theme, max(num) FROM pages GROUP BY theme; theme max(num) ---------- ---------- 1 10 2 100 3 100
Здесь сначала происходит группировка записей по темам. Потом в каждой группе ищется запись с максимальным значением столбца num.
Для вывода можно указывается столбец таблицы, группировка по которому не выполняется:
sqlite> SELECT title,theme,max(num) FROM pages GROUP BY theme; Amount of Information|1|10 Binary System|2|100 Boolean Lows|3|100
В примере выше это поле title. Однако подобное не всегда уместно:
sqlite> SELECT title, theme, count() FROM pages GROUP BY theme; What is Information|1|2 Binary System|2|1 Boolean Lows|3|1
У нас две страницы первой темы, но поскольку мы выводим в одной строке целую группу, название другой страницы первой темы не показано. Таким образом, хотя можно указывать столбцы по которым группировка не выполняется, иногда в этом нет смысла.