Типы данных в Kotlin
В начале предыдущего урока было сказано, что данные бывают разных типов. И хотя мы присваивали переменным только строки, ничего не мешает связывать их с числами, как целыми, так и вещественными (дробными).
fun main() { val s = "Hello" val i = 2 var f = 1.34 println(s) println(i + f) // выведет 3.34 }
Kotlin относится к языкам со статической типизацией. Это значит, что у переменных есть тип, и его нельзя поменять. Их тип статичен, то есть постоянен. Например, если в приведенном выше коде мы попробуем присвоить переменной f новое значение, которое не является вещественным числом, то встроенный в IntelliJ IDEA анализатор кода сообщит об ошибке. Если мы проигнорируем и попытаемся скомпилировать проект, на ту же самую ошибку укажет уже компилятор.
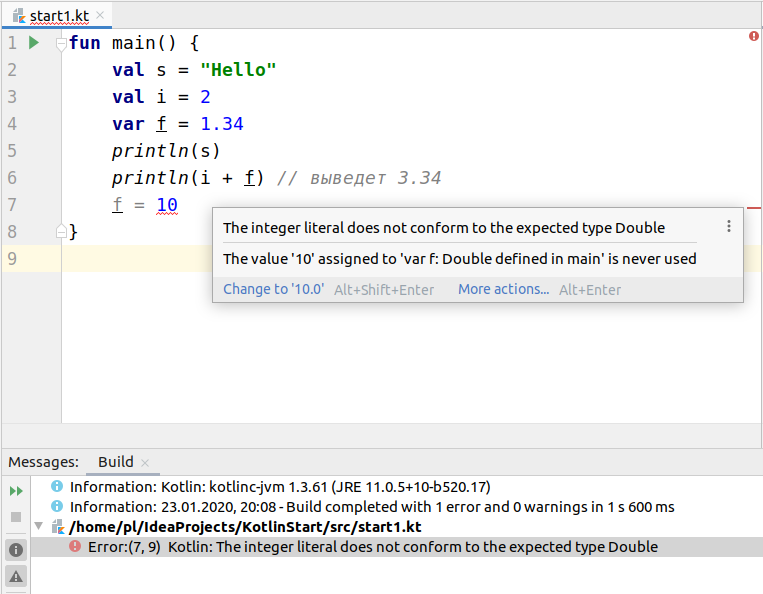
В данном случае ошибка гласит "The integer literal does not conform to the expected type Double", что можно перевести как "Целочисленный литерал не подходит к ожидаемому типу Double". Double – это один из типов вещественных чисел. Литералами в программировании называют известные значения простых типов. IntelliJ IDEA предлагает нам исправить ошибку путем присваивания литерала 10.0 – вещественного числа с нулевой дробной частью. Однако обратим внимание на другое.
Мы нигде не указывали, что переменная f должна быть типом Double. Почему же ее посчитали таковой? На самом деле мы указали ее тип, но не явно. Тип переменной был выведен из присвоенного ей инициирующего (начального) значения. Компилятор посмотрел на число 1.34 и определил, что оно типа Double. А поскольку мы его присваиваем в том же выражении, в котором объявляем переменную, он сделал вывод, что переменная f должна быть соответствующего типа. Аналогично произошло и с другими переменными – их тип определился как String и Int. В IntelliJ IDEA чтобы увидеть тип переменной, надо установить на нее курсор и нажать Ctrl + Shift + P.

В большинстве других языков со статической типизацией нет таких умных компиляторов, способных выводить тип переменной, исходя из ее значения. Поэтому там тип задается явно. Мы можем явно задавать тип и в Kotlin. Однако, если присваивание идет сразу, это излишне. А вот если нет, тогда явное задание типа – единственный вариант объявления переменной.
import kotlin.random.Random fun main() { val s: String = "number: " val i: Int = Random.nextInt(1,10) val f: Double if (i > 5) f = i * 1.5 else f = i * 2.0 println(s + i) println(f) }
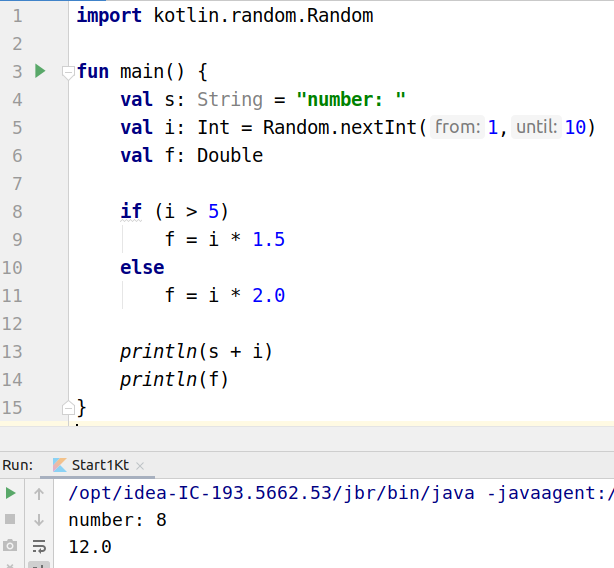
Рассмотрим подробно приведенную выше программу. В Kotlin объявление переменной с явным указанием типа имеет такой синтаксис:

Переменной s сразу присваивается значение, по которому можно вывести ее тип. Поэтому явно ее тип можно было бы не указывать, о чем сообщает IntelliJ IDEA окрашивая излишества в серый цвет.
Переменной i также сразу присваивается значение, и ее тип Int можно было бы не указывать. Но, видимо, поскольку значение определяется выражением, а не литералом, среда не считает лишним явное указание типа переменной. Так код яснее.
Переменной f мы не присваиваем никакого инициирующего значения, поэтому ее тип должен быть обязательно указан явно.
Выражение Random.nextInt(1, 10) генерирует случайное целое число от 1 до 9 включительно. Слова from и until, которые вы видите на изображении, не пишутся. Их высвечивает среда для удобства, чтобы было понятно, какие параметры определены в функции nextInt.
Функция-метод nextInt принадлежит объекту Random, который мы импортируем из стандартной библиотеки Kotlin выражением import kotlin.random.Random. Слово kotlin – это имя библиотеки, random – имя пакета в ней. Пакет – это подкаталог, находящийся в каталоге kotlin, а Random – это объект, находящийся в одном из файлов пакета random. Там запрограммирована логика работы функции nextInt. Чтобы пользоваться этой функцией, понимать принцип ее работы нам не обязательно. Достаточно знать, что в нее передается, и что она возвращает.
Выражение импорта можно не вводить вручную, при попытке воспользоваться функцией среда сама предложит импортировать то или иное из установленных и подключенных библиотек. Или автоматически импортирует, если выбор однозначен, когда вы уже пишите имя функции, которая встречается только в одном пакете.
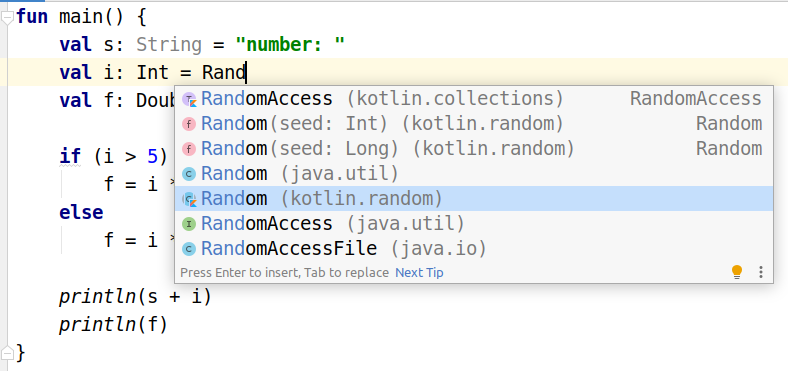
В списке автодополнения надо выбрать то, что вам надо, и нажать Enter. Если же импорта не произошло (так бывает при вставке готового куска кода), то IntelliJ IDEA выделяет неизвестные объекты красным цветом. Надо установить курсор в выделенное слово и навести на него указатель мыши, после чего появится сообщение, предлагающее выполнить импорт нажатием Alt + Enter.

Ниже объявления переменных в программе используется условный оператор if-else, который будет изучаться позже. Пока достаточно знать, что если значение i больше 5, то f будет присвоено значение i, умноженное на 1.5, во всех остальных случаях – умноженное на 2.
Цель этого примера показать, что первое значение переменной не обязательно присваивать сразу. Бывают ситуации, когда это происходит позже в коде. Конечно, можно там же и объявить переменную. Однако придание программному коду структуры, объявление всех используемых переменных в начале делает код более понятным. Такой код легче понимать и обслуживать.
Вернемся к рассмотрению типов данных. С учетом всех возможных библиотек, которые можно импортировать, типов-классов огромное количество. Однако выделяют так называемые базовые типы, к которым в Kotlin относят все числовые типы, булевый, символьный, а также строки и массивы. Числа, булевый тип и символьный также являются примитивными типами.
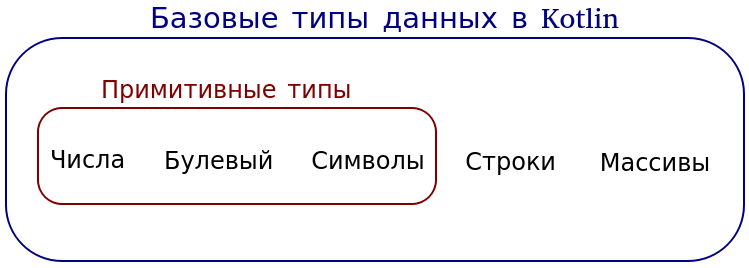
Булевый, символьный и строковый типы представлены каждый одним классом (не считая типов с поддержкой null, которые мы не будем здесь рассматривать). Соответственно, Boolean, Char и String. Для чисел и массивов существует множество классов.
Так классы чисел в первую очередь подразделяются на целочисленные и вещественные. Основными классами целых являются Byte, Short, Int и Long. Вещественных классов два – Float и Double. Предел значений типа Byte – от -128 до 127 включительно, типа Long – девятнадцатизначное число. Float вмещает меньшую длину дробной части по-сравнению с Double.
Когда вы присваиваете целое или вещественное значение без явного объявления типа, они будут автоматически определены как Int или Double. Однако если целое число выходит за диапазон типа Int, лежащий в границах от -2147483648 до 2147483647, то для переменной устанавливается тип Long.
У литералов типа Float в конце обязательно должна стоять буква F или f. К литералам типа Long можно приписывать букву L.

Значениями переменных символьного типа Char являются отдельно взятые символы. Для обозначения символьного литерала используются одинарные кавычки.
fun main() { val ch = 'w' val uniChar: Char = '\u27F0' println(ch) println(uniChar) }

Символы можно выражать через их шестнадцатеричный код по таблице символов Юникод. Так в примере выше в литерале обратный слэш (\) и буква u говорят, все что далее следует интерпретировать как код символа (27F0). С помощью таких кодов можно выводить символы, которых нет на клавиатуре, в том числе весьма причудливые.
Подобные комбинации обратного слэша с определенной буквой после него называют – эскейп-последовательностями. Сочетание формирует либо особый символ, который не имеет видимого обозначения, либо экранирует обычный символ, который в языке программирования что-то значит, но его надо вывести как есть, экранировать (убрать) его значение.
Переменные булевого, или логического, типа могут принимать всего два значения. Либо true, либо false. Либо истина, либо ложь. Значения булевого типа возвращаются в результате выполнения логических выражений – обычно сравнения чего-то с чем-то, когда ответ может быть только "да" или "нет". Мы использовали одно из таких логических выражений выше в условном операторе if-else, когда сравнивали значение переменной i с числом 5.
Другой пример:
import kotlin.random.Random fun main() { val b1: Boolean = true val b2 = false val i = Random.nextInt(10) val b3 = i > 5 println(i) println(b3) println(b1 > b2) }

В примере переменные b1, b2 и b3 имеют тип Boolean. Переменная i содержит случайное число от 0 до 9 включительно. Значение b3 зависит от значения i. Если значение i больше пяти, то b3 будет присвоено true, иначе – false.
В программировании истина больше лжи. Поэтому выражение b1 > b2 возвращает истину. Здесь следует обратить внимание, что сравнивать мы можем не только числа, но и объекты других типов. А вот принцип, согласно которому происходит сравнение, определяется предусмотренным для этого кодом, который находится в классе, которому принадлежит данный объект.
Так, если попробуем сравнить две строки, то они будут сравниваться лексикографически – по буквам, а не, скажем, по длине. В примере ниже, вторая буква строки "acd" больше, чем вторая буква строки "abcd", так как 'c' стоит дальше от начала алфавита, чем 'b', и имеет больший соответствующий ей числовой код.
fun main() { println("acd" > "abcd") // выведет true }
Практическая работа:
-
Используя функцию
nextDouble()объектаRandom, напишите код, выводящий на экран случайное вещественное число от 0 до 1, а также случайное вещественное от -2 до 2. -
Разные типы данных занимают разный объем памяти. С помощью свойства
SIZE_BYTESвыведите на экран размер, который выделяется под каждый экземпляр целочисленных типов данных. Пример:println(Int.SIZE_BYTES). -
Какой результирующий тип данных получится при сложении целого и вещественного числа, двух целых разных типов, "сложении" числа и строки?